
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 계정추상화
- ethers websocket
- redux toolkit 설명
- git rebase
- ethers type
- Vue
- Vue.js
- 스마트 컨트렉트 함수이름 중복
- erc4337 contract
- cloud hsm 사용하기
- cloud hsm 서명
- erc4337
- 컨트렉트 동일한 함수이름 호출
- redux 기초
- 러스트기초
- 스마트컨트렉트 예약어 함수이름 중복
- 오블완
- rust 기초
- ambiguous function description
- vue기초
- SBT표준
- 러스트 기초 학습
- ethers v6
- 머신러닝기초
- 체인의정석
- 스마트컨트렉트 함수이름 중복 호출
- ethers typescript
- 티스토리챌린지
- cloud hsm
- 러스트 기초
- Today
- Total
체인의정석
Machine Learning - 머신러닝의 평가 기준 (Confusion Matrix, Accuracy, precision, recall, Inductive Bias, 오캄의 면도날) 본문
Machine Learning - 머신러닝의 평가 기준 (Confusion Matrix, Accuracy, precision, recall, Inductive Bias, 오캄의 면도날)
체인의정석 2023. 12. 1. 20:59https://white-joy.tistory.com/9
머신러닝 = 추론 + 자료구조 + 알고리즘 이다.
Confusion Matrix (혼동행렬, 오차행렬)
먼저 분류 모델을 평사하는 척도로 Confusion Matrix가 있다고 한다.
출처:
분류 모델 성능 평가 지표(Accuracy, Precision, Recall, F1 score 등)
분류 모델(classifier)을 평가할 때 주로 Confusion Matrix를 기반으로 Accuracy, Precision, Recall, F1 score를 측정한다. Confusion Matrix(혼동 행렬, 오차 행렬) 분류 모델(classifier)의 성능을 측정하는 데 자주 사용
white-joy.tistory.com
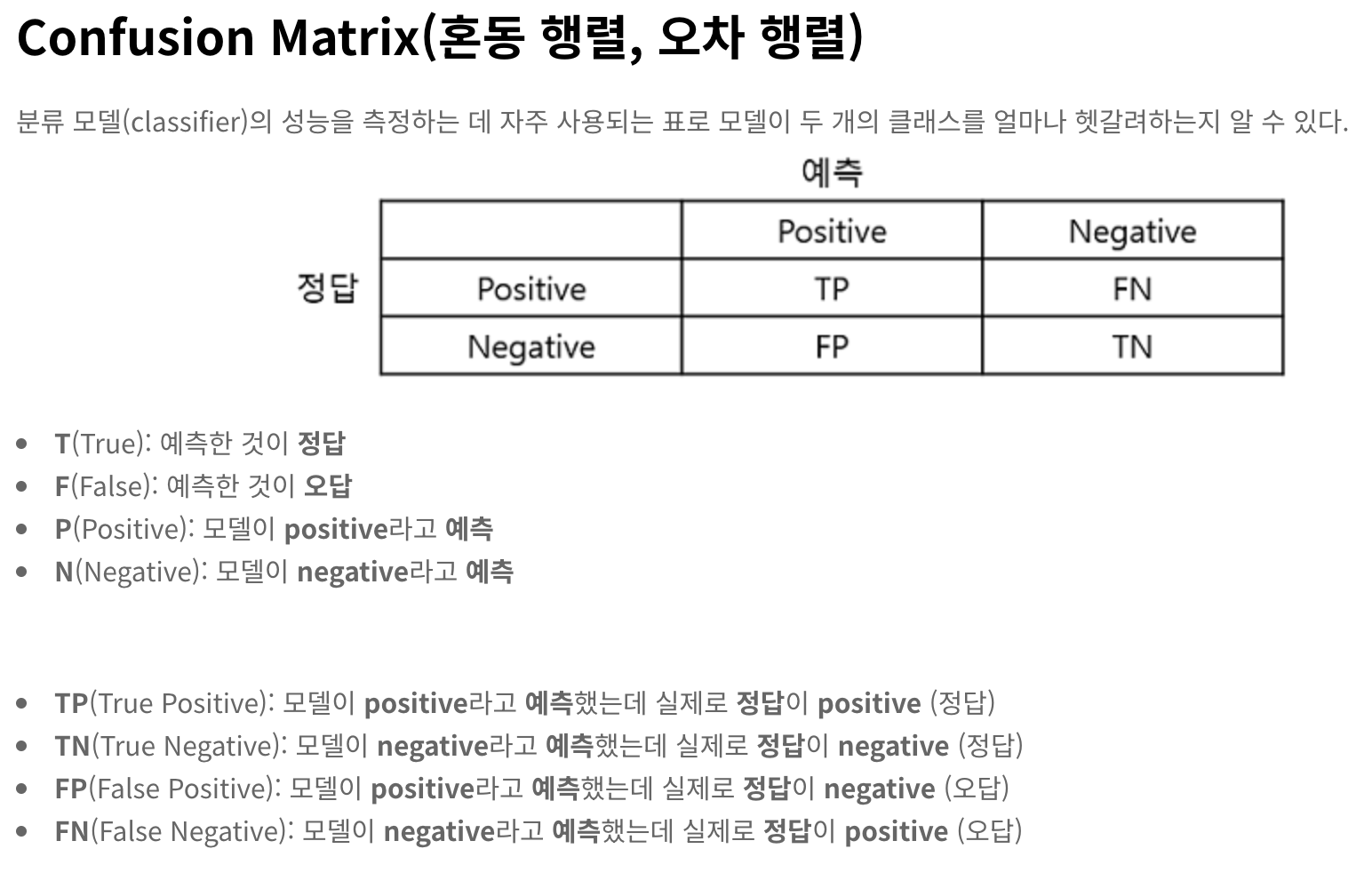
N: Total number of instances in the data set
전체 경우의 수를 모두 보았을 때, 만약 머신러닝의 결과가 긍정적일것이라고 생각했는데 맞추거나, 부정적이라고 생각했는데 맞추거나 하는 케이스가 존재한다.
TP(c): True Positives for class c, - 답변이 잘 맞을것으로 예측한걸 잘맞춤 (정답)
FP(c): False Positives for class c - 답변이 잘 맞을것으로 예측한걸 틀림(오답)
TN(c): True Negatives for class c, - 답변이 맞을것으로 예측한것인데 실제로도 맞음(정답)
FN(c): False Negatives for class c - 답변이 안 맞을것으로 예측했는데 실제로 안맞음(오답)
TP: True Positives over all classes - 정답의 집합
Accuracy => TP/N
전체 모델 중에서 정답에 해당하는 비율을 뽑아내는 것이다. 그러나 긍정, 부정 데이터의 중요도나 균형에 대해서 판단하기 위해 더 세부적인 평가 기준을 만든다.

Precision/Specificity(c) = TP(c) / TP(c)+FP(c)
긍정이라고 예측한 것들 중 실제로 정답이 긍정인 비율로 상황에 따라서 부정인 데이터를 긍정으로 예측하게 되면 안되는 경우에 중요한 지표가 된다.

Recall/Sensitivity(c) = TP(c) /TP(c)+FN(c) 재현률, 민감도
Recall은 긍정으로 생각되는 비율 중에서 실제로 긍정이라고 예측한 비율이다. 만약 정답인데 부정이 있으면 안되는 부분이 있다면 해당 모델이 중요하다.

일반화의 오류 Inductive Bias 와 오캄의 면도날
https://re-code-cord.tistory.com/entry/Inductive-Bias%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
Inductive Bias란 무엇일까?
머신러닝에서 Bias는 무슨 의미일까? Inductive Bias라는 용어에서, Bias라는 용어는 무엇을 의미할까? 딥러닝을 공부하다 보면, Bias과 Variance를 한 번쯤은 들어봤을 것이다. Bias는 타겟과 예측값이 얼
re-code-cord.tistory.com
출처: https://re-code-cord.tistory.com/entry/Inductive-Bias란-무엇일까 [re-code-cord:티스토리]Inductive Bias라는 용어에서, Bias라는 용어는 무엇을 의미할까? 딥러닝을 공부하다 보면, Bias과 Variance를 한 번쯤은 들어봤을 것이다. Bias는 타겟과 예측값이 얼마나 멀리 떨어져 있는가, 그리고 Variance는 예측값들이 얼마나 퍼져있는가를 의미한다. 따라서 Bias가 높은 경우 데이터로부터 타겟과의 연관성을 잘 찾아내지 못하는 과소적합(Underfitting) 문제가 발생하고, Variance가 높은 경우에는 데이터의 사소한 노이즈나 랜덤한 부분까지 민감하게 고려하는 과적합(Overfitting) 문제가 발생한다.
이렇게 발생하는 Bias의 경우 Variance 와 트레이드 오프 관계가 생기게 되기 때문에 이를 잘 조절해 주어야 한다고 한다.
이러한 평가 기준이 있지만 평가기준에 대한 분류가 비슷할때는 "오캄의 면도날" (두 가지 비슷한게 잇다면 비용이 더 적은 것을 선택) 원칙을 적용한다. 피팅이 과적합 한 모델과 트레이닝이 조금 된 모델 중 정확도가 비슷하게 평가된다면 피팅이 덜 된 모델을 선택한다는 것이다.
'빅데이터&인공지능 > 인공지능' 카테고리의 다른 글
| Google GEMINI CLI 사용하여 소스코드 쉽게 분석하기 (1) | 2025.06.26 |
|---|---|
| 사내 강의 정리) 프라이버시 보장 AI 학습을 위한 Security 방법론 (0) | 2024.08.08 |
| 1차 논리 추론 , first order inference 에 대해 알아보자! (1) | 2023.11.04 |
| 1차 논리 , First Order Logic 에 대해 이해해보자! (1) | 2023.11.04 |
| 강화학습 알고리즘 (Two-ply game tree , Alpha-Beta purning, Monte Carlo Tree Search) (0) | 2023.10.07 |


