
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- cloud hsm 서명
- Vue.js
- 체인의정석
- cloud hsm
- ethers v6
- cloud hsm 사용하기
- 티스토리챌린지
- ethers type
- 러스트 기초
- erc4337
- 계정추상화
- 러스트 기초 학습
- 컨트렉트 동일한 함수이름 호출
- 러스트기초
- git rebase
- ethers typescript
- 스마트컨트렉트 예약어 함수이름 중복
- ethers websocket
- redux toolkit 설명
- erc4337 contract
- rust 기초
- vue기초
- 스마트 컨트렉트 함수이름 중복
- redux 기초
- 스마트컨트렉트 함수이름 중복 호출
- 머신러닝기초
- Vue
- SBT표준
- ambiguous function description
- 오블완
- Today
- Total
체인의정석
머신러닝 스터디 02-선형회귀(회귀편)KNeighborsClassifier 분석, k-최근접 이웃 회귀 본문
우선 들어가기에 앞서서 잘 모르고 있던 파이썬 문법을 학습해 보았습니다.
for 문에 변수가 2개인 경우입니다.
https://ponyozzang.tistory.com/578
Python for문 변수 2개 사용 방법
for 문을 사용하다 보면 인덱스가 2개 필요한 경우가 있습니다. 인덱스가 2개 필요한 경우에는 for 문에도 변수를 2개 설정을 해줘야 합니다. for 문에서 변수를 2개 설정하는 방법을 예제로 알아보�
ponyozzang.tistory.com
여러개의 오브젝트나 리스트 등을 for 문에서 동시에 사용하고 싶은 경우에는 zip 함수를 사용해 반복문을 실행할 수 있습니다.
for 문에 2개의 리스트를 지정한 경우에는 변수도 2개를 설정해야 합니다.
names = ['Alice', 'Bob', 'Charlie']
ages = [24, 50, 18]
for name, age in zip(names, ages):
print(name, age)
#결과
# Alice 24
# Bob 50
# Charlie 18따라서 책에 있던 아래 코드는 각각 그래프에 다른 개수의 이웃을 가진 모델을 매칭시켜서 그려주기 위한 코드임을 알 수 있었습니다.
for n_neighbors, ax in zip([1,3,9],axes):
#n_neighbors 1, ax 0,
#n_neighbors 3, ax 1,
#n_neighbors 9, ax 2,
#이웃이 1~9개일때의 결정경계값
K 이웃근접 분류 코드도 아래와 같이 3개를 반복시켜서 이웃이 다를때의 변화를 한번에 출력시켰습니다.
fig, axes = plt.subplots(1,3,figsize=(10,3)) # 평면의 크기조절
for n_neighbors, ax in zip([1,3,9],axes):
clf= KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
mglearn.plots.plot_2d_separator(clf,X,fill=True,eps=0.5,ax=ax,alpha=.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
ax.set_title("{}이웃".format(n_neighbors))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend(loc=3)
왼쪽을 보면 경계가 데이터에 가깝고 이웃의 수를 늘릴 수록 경계가 더 부드러워짐을 확인할 수 있었습니다. 부드러운 경계는 더 단순한 모델을 의미하며, 따라서 이웃을 적게 사용하면 모델의 복잡도가 높아지고 많이 사용하면 복잡도가 낮아집니다. 이웃을 많이 사용하게 되어 극단적으로 모든 데이터를 적용시키면 모든 테스트 포인트에 대한 예측이 모두 같은 값이 되게 됩니다.
이와 같이 모델의 복잡도와 일반화 사이의 관계를 입증하기 위하여 유방암 데이터셋을 이용하여 살펴보겠습니다.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train,X_test,y_train,y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf=KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="훈련 정확도")
plt.plot(neighbors_settings, test_accuracy, label="테스트 정확도")
plt.ylabel("정확도")
plt.xlabel("n_neighbors")
plt.legend()1~11 사이로 이웃의 수를 적용시키면서 실습을 진행합니다.
진행할 시 아래와 같이 표가 나오게 되며, 1~11까지 clf 객체로 k근접법을 적용시킨 후 train을 한 후 트레이닝 정확도에 점수를 테스트 정확도에 점수를 각각 넣은 후, plt.plot을 이용하여 그래프를 그리고 레이블을 설정해주는 코드입니다.

이 그래프를 보면 과대적합과 최소적합의 특징을 발견할 수 있습니다. 여기서는 1이 더 복잡한것이므로 과소 적합이 10으로 두고 과대적합을 1일때로 두면 동일한 원칙이 나옴을 알 수 있습니다. 훈련세트로 봤을때는 1이 가장 복잡하게 나와 정확도가 높지만 실제 테스트 데이터로 봤을 때는 과대적합이 일어나서 정확도가 낮고, 반대로 훈련세트가 10일때는 가장 단순하게 나와서 정확도가 낮으며, 과소 적합이 일어나 마찬가지로 테스트 때도 정확도가 낮습니다. 따라서 6일때 정확도가 가장 높게 되는 것입니다.
K-최근접 이웃 회귀
K-최근접 이웃 알고리즘은 회귀 분석에도 쓰입니다. 아래는 wave 데이터셋을 사용하여 이웃이 하나인 최근접 이웃을 사용한 것입니다. x 축에 3개의 테스트 데이터를 흐린 별 모양으로 표시했습니다. 최근접 이웃을 한 개만 이용할 때 예측은 그냥 가장 가까운 이웃의 타깃값입니다. 이 예측은 진한 별 모양으로 표시하였습니다. 보면 test data는 데이터에서 가장 가까운 값을 찾아서 그 수치와 연결된 것을 볼 수 있습니다.
mglearn.plots.plot_knn_regression(n_neighbors=1)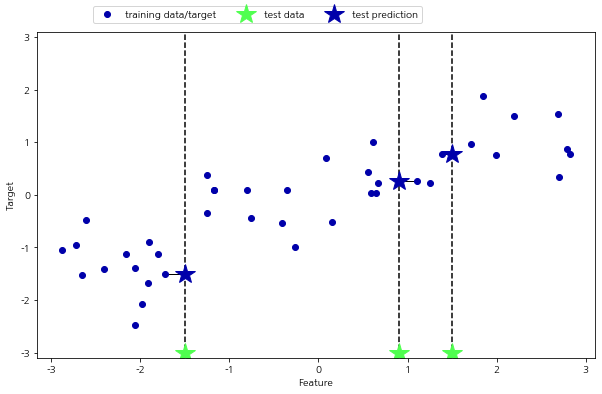
여기서도 이웃을 둘 이상 사용하여 회귀 분석을 할 수 있는데, 여러 개의 최근접 이웃을 사용할 땐 이웃 간의 평균이 예측이 됩니다.
mglearn.plots.plot_knn_regression(n_neighbors=3)
테스트 데이터를 보면 가장 가까운 값 3개의 평균 값에 찍힌 것을 볼 수 있습니다.
from sklearn.neighbors import KNeighborsRegressor
X,y = mglearn.datasets.make_wave(n_samples=40)
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
reg=KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train,y_train)
KNeighborsRegressor(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=3, p=2, weights='uniform')
print("테스트 세트 예측: \n{}".format(reg.predict(X_test)))테스트 세트 예측: [-0.05396539 0.35686046 1.13671923 -1.89415682 -1.13881398 -1.63113382 0.35686046 0.91241374 -0.44680446 -1.13881398]
print("테스트 세트 R^2:\n{}".format(reg.score(X_test,y_test)))테스트 세트 R^2: 0.8344172446249604
score 메서드는 모델을 평가하는데 사용하여 여기서는 회귀 모델을 평가하게 됩니다. 회귀 모델을 평가할때는 결정계수를 구하게 됩니다.
<결정계수>
여기서 R^2(R스퀘어)는 결정 계수라고도 하며 회귀 모델에서 예측의 적합도를 0과 1사이의 값으로 계산한 것입니다. 1은 예측이 완벽한 경우이고, 0은 훈련 세트의 출력값인 y_train의 평균으로만 예측하는 모델의 경우입니다. 정답값에서 얼마나 값이 떨어졌는지를 0~1사이의 수치로 나타낸 것을 이 결정계수로 볼 수 있습니다.
KNeighborsRegressor 분석
1차원 데이터셋에 대하여 가능한 모든 특성 값을 만들어 예측해 볼 수 있습니다.
이를 위해 x 축을 따라 많은 포인트를 생성해 테스트 데이터셋을 만듭니다.
먼저 그래프를 3개를 만든 후 사이즈를 지정해줍니다.
그 후 line이라는 변수를 통해서 -3~3사이에 1000개의 데이터 포인트를 만들었음을 확인 할 수 있습니다.
이후에는 1,3,9개의 이웃에 대해서 각각 이웃 값을 지정해 주고 각각의 표(ax)를 1,3,9와 같이 선택되도록 설정해 줍니다.
반복문 안에서는 이웃의 개수를 정한후 ,fit으로 데이터를 지정한 후 predict를 통해 예측을 하고 이를 ax표에 각각 그리는 과정을 진행합니다. 테스트와 트레인 데이터로 나누어서 각각 다른 보양으로 그래프를 그립니다. 마지막으로 레전드로 표기를 해준 후 출력을 진행합니다.
fig, axes = plt.subplots(1,3, figsize=(15,4))
line = np.linspace(-3,3,1000).reshape(-1,1)
for n_neighbors, ax in zip([1,3,9],axes):
reg=KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train,y_train)
ax.plot(line, reg.predict(line))
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0),markersize=8)
ax.plot(X_test,y_test, 'v', c=mglearn.cm2(1),markersize=8)
ax.set_title(
"{} 이웃의 훈련 스코어: {:.2f} 테스트 스토어:{:2f}".format(
n_neighbors, reg.score(X_train, y_train),
reg.score(X_test,y_test))
)
ax.set_xlabel("특성")
ax.set_ylabel("타깃")
axes[0].legend(["모델 예측", "훈련 데이터/타깃", "테스트 데이터/타깃"], loc="best")
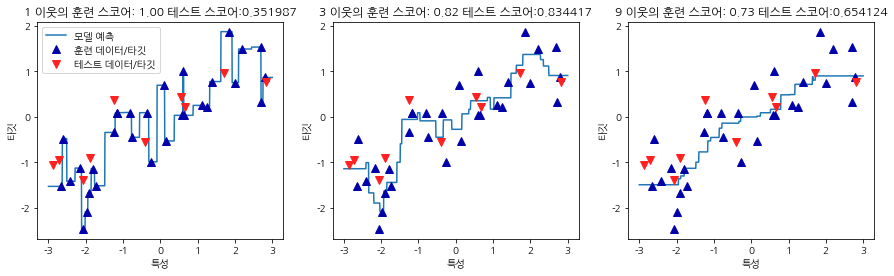
이 결과를 보게 되면 이웃을 1개를 사용하였을때는 훈련 세트의 각 데이터 포인트가 예측에 주는 영향이 크기 때문에 예측값이 훈련 데이터 포인트를 모두 지나가게 됩니다. 반면 이웃을 많이 사용하면 훈련데이터는 잘 안맞는데신 더 안정된 예측을 얻게 됩니다.
장단점과 매개변수
KNN은 이해하기는 쉽지만 훈련세트가 크면 예측이 느려지며, 특성이 수백개 이상이 될 경우 잘 작동되지 않으며, 특성 값이 희소한 데이터셋과는 잘 작동하지 않아 현업에는 거의 사용되지 않습니다. 따라서 학습용으로만 보고 넘어가변 된다고 합니다.
참고 서적
파이썬 라이브러리를 활용한 머신러닝
github 주소
https://github.com/hynki95/machine_learning
hynki95/machine_learning
Contribute to hynki95/machine_learning development by creating an account on GitHub.
github.com
유튜브 주소
https://www.youtube.com/results?search_query=%ED%83%80%EC%9E%84%ED%95%B4%EC%BB%A4
타임해커 - YouTube
블록체인/인공지능 -웹개발(프론트/백) -광고(페이스북/구글/네이버) -사업계획서 작성 -비전공생을 위한 IT 공부법 채널이름은 기획, ... 구독구독중구독 취소
www.youtube.com
'빅데이터&인공지능 > 인공지능' 카테고리의 다른 글
| 머신러닝 스터디 02-선형모델(분류 편)- 다중 클래스 분류용 선형 모델 (0) | 2020.08.10 |
|---|---|
| 머신러닝 스터디 02-선형모델(회귀 편)선형회귀,릿지회귀,라쏘회귀 (0) | 2020.07.12 |
| 머신러닝 스터디 02- 지도학습(분류 & 회귀) (0) | 2020.07.07 |
| 머신러닝 스터디 01 - 지도학습 vs 비지도 학습, Iris data 예시 (3) | 2020.07.05 |
| AI) 공부 일기 - CNN 코드 기본 분석 (1) | 2020.05.31 |



