
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ethers websocket
- ethers v6
- redux 기초
- cloud hsm 서명
- 스마트컨트렉트 함수이름 중복 호출
- 러스트 기초
- cloud hsm
- rust 기초
- ethers type
- 티스토리챌린지
- ambiguous function description
- vue기초
- 러스트 기초 학습
- Vue.js
- 컨트렉트 동일한 함수이름 호출
- cloud hsm 사용하기
- erc4337
- 오블완
- SBT표준
- ethers typescript
- 스마트 컨트렉트 함수이름 중복
- erc4337 contract
- git rebase
- 머신러닝기초
- 체인의정석
- 계정추상화
- 러스트기초
- Vue
- 스마트컨트렉트 예약어 함수이름 중복
- redux toolkit 설명
- Today
- Total
체인의정석
AI) 공부 일기 - CNN 코드 기본 분석 본문

인공지능 첫걸음 CNN- 활성화 함수
1. 활성화 함수 - 입력을 받아 활성, 비활성을 결정하는데 사용되는 함수
선형/비선형
선형함수 = 직선 모양 - y=ax+b
비선형 함수 = 2개 이상의 직선/곡선 모양 - Sigmoid/Relu
2개 분류하는 문제 = Vanisihing Gradient Problem 때문에 sigmoid 대신 Relu와 변형된 활성화 함수 주로 사용
3개 이상을 분류 = Softmax와 변형된 활성화함수 주로 이용
은닉층을 여러 개 다층으로 구성하고 활성화 함수로 모두 선형함수를 이용하면 단층으로 구성하는것과 동일하게 구성할 수 있다고 한다. 따라서 깊게 망을 구성하려면 1개 이상의 비선형 함수를 이용하여야 한다.
Sigmoid 계열 - 모두 S 형태, 입력값이 증가함에 따라 결과값이 증가만 계속 됨 (단조증가)
어떤 경향을 보인다~로 해석 가능. 기울기가 점차 증가하다가 0 부근에서 기울기가 점차 감소함을 알 수있다.

ReLu 계열은들은 0 이상인 경우는 그대로 두고 0보다 작은 음수의 경우에는 모두 0으로 나온다.
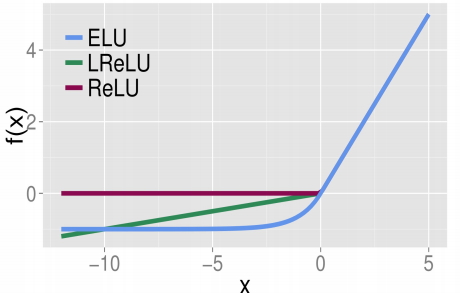
이미지 및 원문 출저 : https://m.blog.naver.com/wideeyed/221017173808
[딥러닝] Activation Function(활성화 함수) 소개 및 비교
활성(화)함수란 입력을 받아 활성, 비활성을 결정하는데 사용되는 함수이다. 그러면 활성화함수들은 어떤 ...
blog.naver.com
Convolution Layer - Conv2D 레이어는 영상 인식에 주로 사용되며 필터가 탑재 되어 있다.
| Conv2D(32,(5,5), padding='valid',input_shape(28,28,1),activation='relu') |
첫번째 인자 - 컨볼루션 필터의 수
두번째 인자 - 컨볼루션 커널의 행,열
padding - 경계 처리 방법 (valid-유효 영역 출력, same- 출력 이미지 사이즈가 입력 이미지 사이즈와 동일)
input_shape - 샘플 수를 제외한 입력 형태를 정의
activation - linear(디폴트 값), relu(은닉층에 사용), sigmoid(이진 분류), softmax(다중 클래스 분류)
Flatten 레이어 - CNN에서 마지막으로 구현하는 전 결합층 에서는 1차원 자료로 바꿔 주어야 하기 때문에 Flatten layer가 쓰이게 됩니다.
| Conv2D(1, (2, 2), padding='valid', input_shape=(3, 3, 1)) |

필터는 가중치를 의미하며 하나의 필터로 입력 이미지를 순회하기 때문에 적용되는 가중치는 모두 동일합니다. 이를 파라미터 공유라고 부릅니다. 이는 학습해야할 가중치 수를 현저하게 줄여줍니다.
| Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 1)) |

| Conv2D(3, (2, 2), padding='same', input_shape=(3, 3, 1)) |

| Conv2D(1, (2, 2), padding='same', input_shape=(3, 3, 3)) |

| Conv2D(2, (2, 2), padding='same', input_shape=(3, 3, 3)) |
| MaxPooling2D(pool_size=(2, 2)) |
MaxPooling - 이것은 지역적인 사소한 변화가 영향을 미치지 않도록 합니다

이미지, 내용 출저 : https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
컨볼루션 신경망 레이어 이야기
이번 강좌에서는 컨볼루션 신경망 모델에서 주로 사용되는 컨볼루션(Convolution) 레이어, 맥스풀링(Max Pooling) 레이어, 플래튼(Flatten) 레이어에 대해서 알아보겠습니다. 각 레이어별로 레이어 구성 �
tykimos.github.io
5/31 회의 내용
데이터 섞는 것은 오염 가능성이 있다.
전이학습 - 딥러닝을 하게 되면
많은 데이터가 필요하게 된다.
그런데 처음부터 모델을 학습하는게 아니라
이미 사람들이 참여하는 이미지에 classification을 하는 대회인 이미지넷을 활용할 수 있다. VGG
CNN레이어 처음부터 끝까지 학습을 하려면 시간이 오래걸리고 한정된 데이터로 할 시 overfitting이 날 수 있다. 이미지는 또한 학습시간이 길기 때문에 이미지넷이라는 대회를 이용하면 좋다. 이미 데이터셋과 데이터셋을 학습시킨 모델을 제공하고 있다. 각각 층마다 역할이 있고 상위 층으로 갈 수록 축적이 된다. 선->면->3D->색까지 어떤 이미지 까지는 공통적인 특성이 있어서 특정 측까지는 재사용이 가능. 이미 학습되어 있는 모델이 있다면 필요한 부분만 학습을 시킬 수 있다. 이를 전이학습이라고 한다. 현업에서 예전에는 처음부터 구현했지만 이미지 쪽은 발달이 많이 되어서 사전학습된 모델을 가지고 전이학습. 내가 원하는 부분만 학습해서 쓰겠다. 모바일넷을 사용할시 시간도 단축되면서 경량화가 어서 빠르다.
VGG -> 데스크탑, 서버에서 학습, 백그라운드가 좀 큰 곳에서 돌아갈 있는 모델, 핸드폰에서도 돌아가게 하려는 것은 이미지넷, VGG와 같이
현업에서는 전이학습을 함. 대기업도 그렇고 데이터를 처음부터 끝까지 돌릴 수 없으며 , 성능이 비슷비슷 하기 때문에,
8할은 데이터 파이프라인 처리 (모델이 학습할 수 있도록 전처리 하는것)
val 이 8개로 너무 작아서 합친 후 다시 뺌
train에 있는게 val에 있는지 &로 체크
전처리 - 라벨 데이터
전이학습의 가장 큰 장점은
Overfitting을 어느정도 잡아주게 된다.
Code에서 테스트를 해볼것.
DenseLayer 추가 등 상위에서만 추가했음.
하지만 MobileNet도 선별해서 학습을 ㅐ볼 수 있다.
전이학습으로 최적화를한 것.
alexnet의 경우 이미지넷의 초창기에 활용됨
지금은 MobileNet쪽을 많이 쓰고 있음. 서비스 를 하기 위해서는 MobileNet이 유용, 데이터 셋이 커져도 가벼움. VGG, Mobile Net 사전 학습된 데이터는 같으며 모바일 넷은 예측하는 속도가 빠름
'빅데이터&인공지능 > 인공지능' 카테고리의 다른 글
| 머신러닝 스터디 02-선형모델(분류 편)- 다중 클래스 분류용 선형 모델 (0) | 2020.08.10 |
|---|---|
| 머신러닝 스터디 02-선형모델(회귀 편)선형회귀,릿지회귀,라쏘회귀 (0) | 2020.07.12 |
| 머신러닝 스터디 02-선형회귀(회귀편)KNeighborsClassifier 분석, k-최근접 이웃 회귀 (0) | 2020.07.11 |
| 머신러닝 스터디 02- 지도학습(분류 & 회귀) (0) | 2020.07.07 |
| 머신러닝 스터디 01 - 지도학습 vs 비지도 학습, Iris data 예시 (3) | 2020.07.05 |



